From this week’s readings, it appears that there has been some disconnect between historians and geographers in the past. However, there has been an effort made by digital historians recently who have gravitated towards geographic information systems (GIS) to link the two fields together for scholarly purposes. Tim Hitchcock suggests that this division was partially due to geographers’ seeking more secure academic funding by aligning themselves with STEM departments rather than with history/humanities and as a result, there has been little dialogue between the two fields. However, the availability of user-friendly GIS programs and mass digitization of historic texts and lots of data, have opened the doors to collaboration between history and geography in a digital format. History can now be geo-referenced, as historical maps can be digitized and layered, as well as analyzed, as the examples covered illustrate.
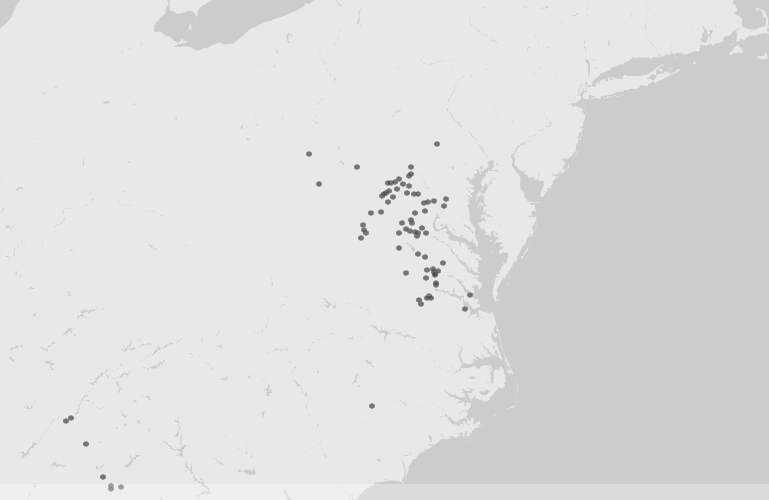
The Visualizing Emancipation project is a prime example of how mapping historical data can reveal patterns through imagery. I could spend all day playing with Visualizing Emancipation. By allowing the user to select an Emancipation Event, such as the “Capture of African Americans by Union troops” or “Conscription/Recruitment” by either the Union or Confederate Armies and filtering by source type, such as book, official records, newspapers and/or personal papers, researchers are able to explore a previously primarily text-based set of documents in a visual geographic manner. This pairing is helpful to those, like myself, who like to match a document to its complete history, including its geography. With adjustable map options, users can choose how they want to visualized the data presented to them and click on specific events to learn about its details. One of the tool’s most handy features is its ability to link directly to the actual source material that is geo-referenced, as it allows users to interpret the data for themselves. The map visualization helps us to take on a new perspective on such a large topic on different scales, allowing us to expand and contract our view of emancipation in a geographic way.
On a smaller scale, geographically, Digital Harlem is somewhat similar to Visualizing Emancipation, in that historical records have been geo-referenced to reveal patterns of daily life in Harlem from 1915 – 1930. By selecting a type of event, the name of a person or place, users can create custom maps that plot each event, with their descriptions as well. Multiple layers can be built on top of a Google map and/or an historical map, helping us to visualize the geographic display of archival sources, such as crime records and newspapers.
With GIS, historians can use maps to explore historical themes, such as with the ORBIS project from Stanford. Both take historical data and apply it to a map, which ORBIS allows researchers to not only map the Roman Empire, but also calculate travel routes with respect to seasonal changes, modes of transportation, and expenses. It differs from the above examples in that it is not a tool to plot specific events, but it models various outcomes by using criteria set by the user based on historical data.
All of the tools covered in this week’s reading each combine history and geography to create customizable and interactive maps that can help us gain a new perspective on the historical record. This pairing has benefited from the digitization of documents and advances in/ increasing availability of GIS software and tools, and I can only see an increase in scholarship that utilizes such tools.