I tracked the usage of the word “railroad” with Google ngram viewer, Bookworm: Chronicling America, and NYT Chronicle and found some interesting results that you can see for yourself below.
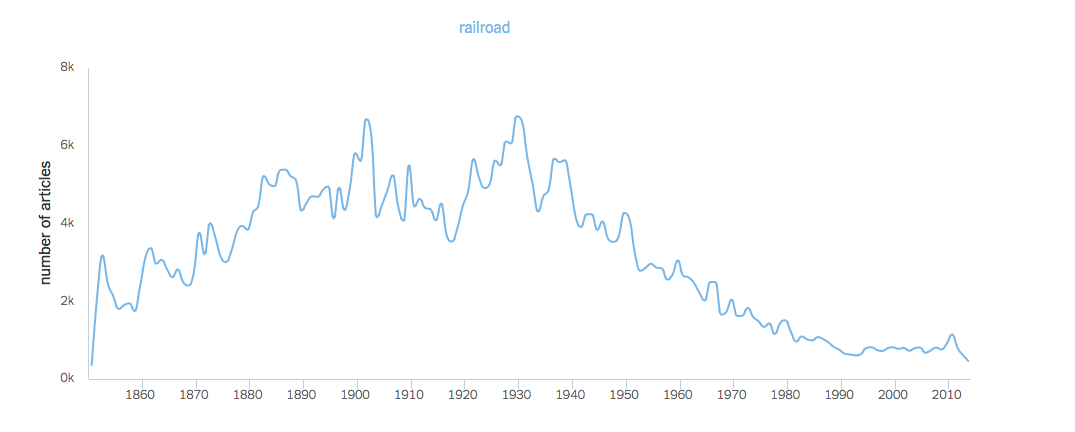
I wanted to see how the word railroad appeared in historic newspapers from the Library of Congress’ Chronicling America collection. I was able to view results from 1840 – 1921 with Bookworm: Chronicling America and saw how the word railroad peaked in 1873 with a frequency rate of 58.9. I expected a larger spike for 1877, the year of the Great Railroad Strike, but this it could be a reflection of the newspapers available in Chronicling America. The Panic of 1873 could very well be the reason for the highest rate of the word I search, since the depression followed a large boom in railroad expansion.
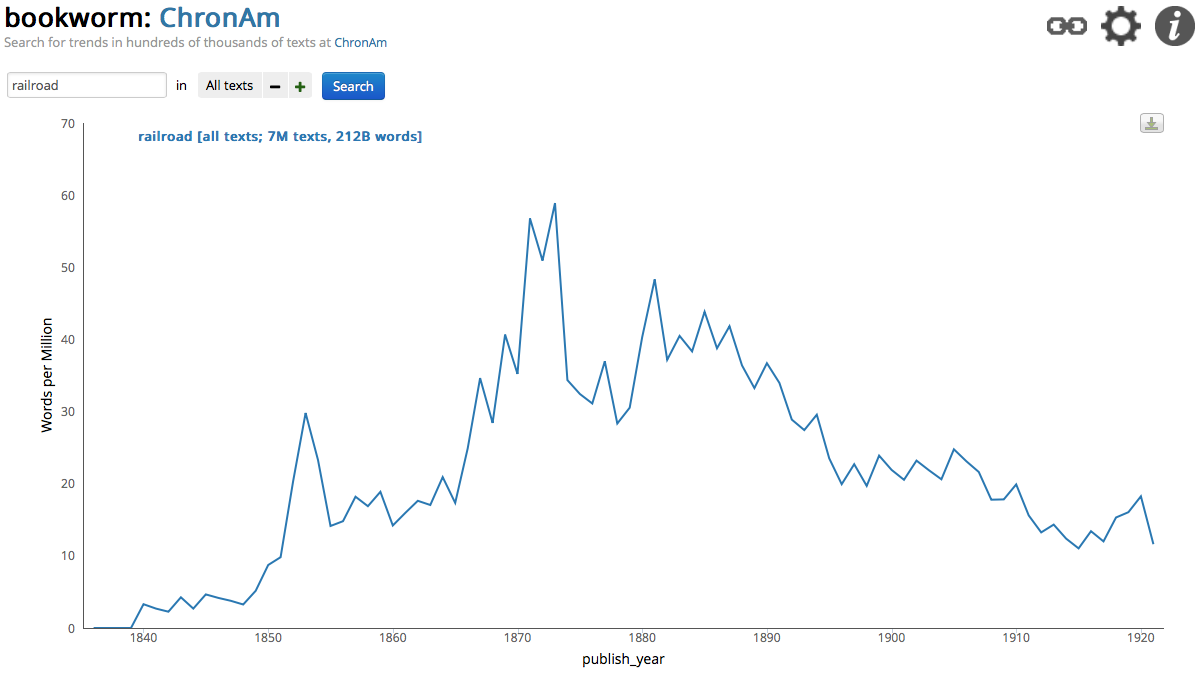
With NYT Chronicle, which only tracks the usage of words in the New York Times, I noticed a different pattern. I changed the default setting to reflect the actual number of articles that mentioned railroad and saw the highest amount in 1930 with 6,763 articles, followed closely in 1902 with 6,682. In 1851, the earliest date available, we see that there were only 357 references to railroad. During the Panic of 1873 there were 4,015 articles that mentioned railroad, after a period of steady rising through the Civil War. After the peak in 1930, a steady decline can be seen, eventually getting down to 616 articles in 2013. So far, in 2014, there have only been 465 articles with the word railroad mentioned.
I used two terms when searching Google Books’ ngram viewer, train and railroad, just to see how they compared. Except for the earliest years searched, 1840 -1860, the two words show up almost with the same frequency, except for a slight dip with railroad between 1890 and 1900. With Google Books, we can’t see where the words are coming from, which is truly a case of distant reading.
When compared to Voyant, the ngram viewers mostly obscure the content that is being text mined. With Voyant, you see the entire corpus that you select to upload, and then see the pattern within that text. For my Voyant example, I uploaded the text of the 1869 diary of Henry Schweigert, a farmer/college student who lived from 1843 – 1923 in southeastern Pennsylvania. He kept diaries from 1869 – 1881 and I have been in the process of transcribing them and so far only have 1869 completed, the year he attended the now defunct Palatinate College in Myerstown, PA. I was curious to see what the patterns were with this text, as I was relatively familiar with the content.
As I expected, the words day and nice show up frequently, as well as college, home and Myerstown. Schweigert’s diary entries are brief and focus on the daily weather, his location, and any events or activities he had during the day. I removed the typical stop words such as the, and, and also the year 1869, as that showed up quite often as it was mentioned in every entry. Other noticeable words are church, excelsior (he was a member of the Excelsior Literary Society), brother and thrashing (as in thrashing wheat).